|
The distinction between abstract and concrete words (such as
dream in contrast to banana) represents a semantic
categorisation highly relevant for Natural Language Processing
(NLP) purposes. In this vein, our project MUDCAT investigates the
notion of abstractness from a data-driven and application-oriented
point of view. While the most long-standing discussions about
abstractness have taken place in the cognitive sciences, we
address and enhance critical issues in existing definitions, data
collections and characterisations, and broaden and optimise the
perspective towards effective exploitation in NLP approaches.
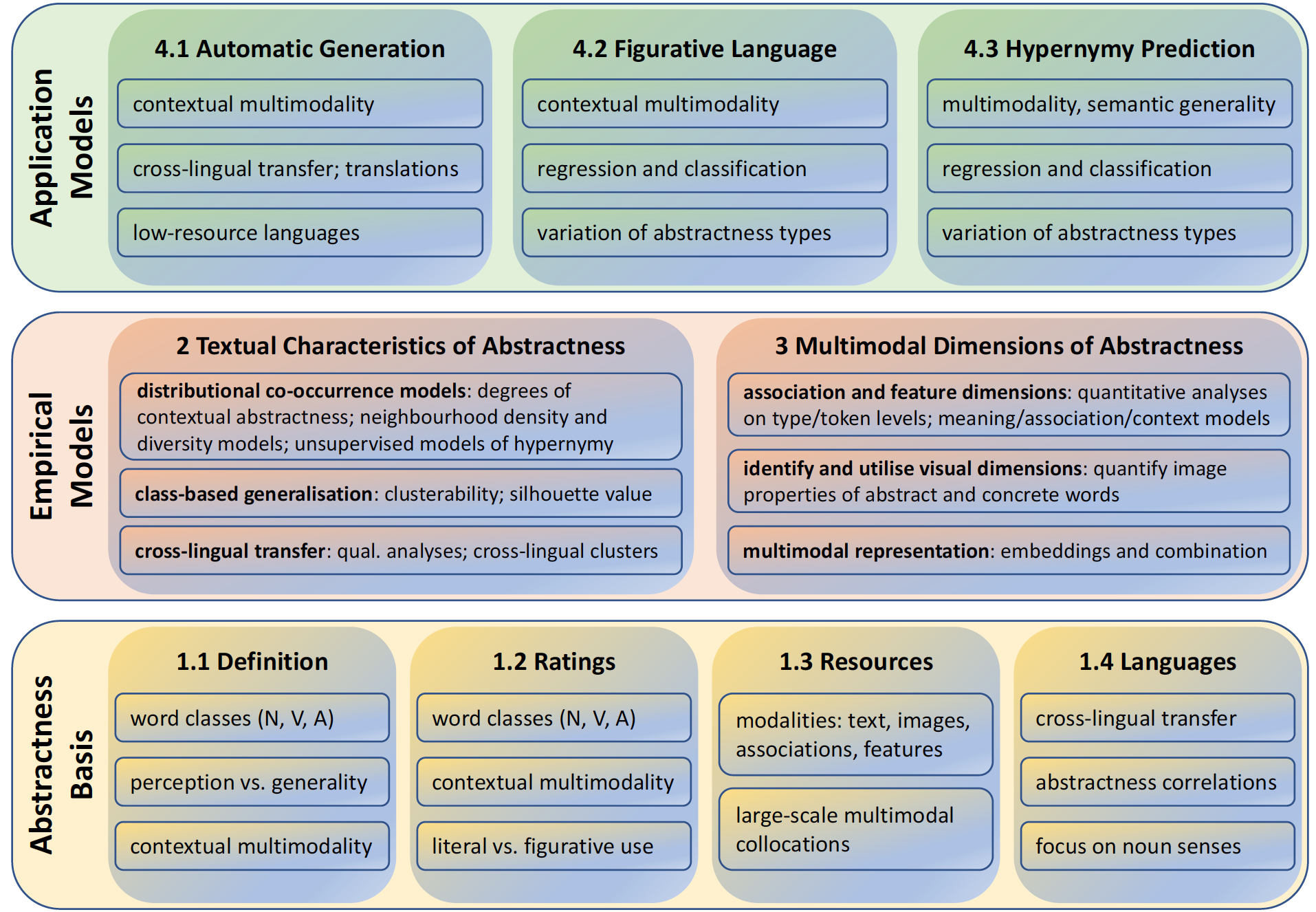
Up to date, definitions, collections and applications of abstractness have mostly been performed on a word-type basis without contextualisation. In contrast, MUDCAT will develop, exploit and apply empirical dimensions of abstractness while paying attention to a token-based, sense-related perspective across word classes (nouns, verbs, adjectives), across modalities (text, associations, features, images) and across languages (English, German, Italian). In this vein, we will collect novel human-generated norms on abstractness and exploit cross-lingual transfer to advance semi-automatic algorithms for norm generation. A major effort at the empirical layer will identify and induce word-class-dependent salient dimensions of abstractness from large-scale corpora, taking into account contextual conditions in the form of syntactic constellations (such as subcategorisation and modification). Considering that abstractness is conceptually distinguished from concreteness on multimodal grounds, we will go beyond the textual dimension and collect and explore multimodal facets of abstractness in free word associations, feature-property generation and images. Class-based and cross-lingual clustering approaches will investigate semantic and language generalisations of the multimodal characteristics. Finally, the multimodal cross-lingual empirical knowledge of abstractness will be applied to NLP tasks whose performance is known or expected to profit from abstractness knowledge. Accordingly, we will develop generic computational approaches to apply our enhanced abstractness information to semantic challenges: figurative language identification as concrete–abstract mapping task, and hypernymy detection as semantic generality task. Overall, MUDCAT will investigate the cross-lingual transferability in definitions and applications of abstract and concrete words for English, German and Italian, while taking ambiguity of targets and contexts into account. |
|
|
| The project MUDCAT is a SemRel project and part of the ongoing collaboration KATER between Jun.-Prof. Diego Frassinelli (University of Konstanz) and Prof. Sabine Schulte im Walde (University of Stuttgart). It is funded by the DFG (Deutsche Forschungsgemeinschaft, the German Research Foundation) under research grant SCHU 2580/4-1. |
Doctoral Researchers
- Urban Knupleš
- Prisca Piccirilli
- Tarun Tater
Student Researchers
- Mohammed Abdul Khaliq
- Sven Naber
- Tonmoy Rakshit
- Katrin Schmidt
Publications
Annerose Eichel, Tonmoy Rakshit, Sabine Schulte im WaldeContextualising (Im)plausible Events Triggers Figurative Language [resource]
In: Proceedings of the Workshop on Learning Non-Literal Expressions with Small Data (NLE). Palma de Mallorca, Spain, May 2026.
Annerose Eichel, Sabine Schulte im Walde
PAP: A Dataset for Physical and Abstract Plausibility and Sources of Human Disagreement [pdf/poster/resource]
In: Proceedings of the 17th Linguistic Annotation Workshop (LAW). Toronto, Canada, July 2023.
Jule Godbersen, Sinan Cem Kurtyigit, Emma Raimundo Schulz, Tonmoy Rakshit, Diego Frassinelli, Sabine Schulte im Walde, Carina Silberer
Fruitcakes and Cupcakes Emerging from Noise: The ComposiGen Dataset of Compounds and their Compositionality [resource]
In: Proceedings of the 15th International Conference on Language Resources and Evaluation (LREC). Palma de Mallorca, Spain, May 2026.
Anna Hülsing, Sabine Schulte im Walde
Cross-Lingual Metaphor Detection for Low- to High-Resource Languages [pdf/resource]
In: Proceedings of the 4th Workshop on Figurative Language Processing. Mexico City, Mexico, June 2024.
Mohammed Abdul Khaliq, Diego Frassinelli, Sabine Schulte im Walde
Comparison of Image Generation Models for Abstract and Concrete Event Descriptions [pdf/resource]
In: Proceedings of the 4th Workshop on Figurative Language Processing. Mexico City, Mexico, June 2024.
Urban Knupleš, Diego Frassinelli, Alexander Fraser, Sabine Schulte im Walde
Literally Concrete or Figuratively Abstract? Multilingual Concreteness Norms for Verb-Object Expressions [preprint pdf/resource]
Transactions of the Association for Computational Linguistics (TACL).
Urban Knupleš, Diego Frassinelli, Sabine Schulte im Walde
Investigating the Nature of Disagreements on Mid-Scale Ratings: A Case Study on the Abstractness-Concreteness Continuum [pdf/poster/supplement]
In: Proceedings of the SiGNLL Conference on Computational Natural Language Learning (CoNNL). Singapore, December 2023.
Sinan Kurtyigit, Diego Frassinelli, Carina Silberer, Sabine Schulte im Walde
A Couch Potato is not a Potato on a Couch: Prompting Strategies, Image Generation, and Compositionality Prediction for Noun Compounds [pdf/resource+code]
In: Findings of the Association for Computational Linguistics: ACL. Vienna, Austria, July/August 2025.
Sven Naber, Diego Frassinelli, Sabine Schulte im Walde
Evaluating Textual and Visual Semantic Neighborhoods of Abstract and Concrete Concepts [pdf/poster/code]
In: Proceedings of the 14th Joint Conference on Lexical and Computational Semantics (*SEM). Suzhou, China, November 2025.
Prisca Piccirilli, Alexander Fraser, Sabine Schulte im Walde
Floating or Suggesting Ideas? A Large-Scale Contrastive Analysis of Metaphorical and Literal Verb-Object Constructions [resource]
In: Proceedings of the Workshop on Cognitive Modeling and Computational Linguistics (CMCL). Palma de Mallorca, Spain, May 2026.
Prisca Piccirilli, Sabine Schulte im Walde
Features of Perceived Metaphoricity on the Discourse Level: Abstractness and Emotionality [pdf/poster/resource/bib]
In: Proceedings of the 13th International Conference on Language Resources and Evaluation (LREC). Marseille, France, June 2022.
Prisca Piccirilli, Sabine Schulte im Walde
What Drives the Use of Metaphorical Language? Negative Insights from Abstractness, Affect, Discourse Coherence and Contextualized Word Representations [pdf/bib]
In: Proceedings of the 11th Joint Conference on Lexical and Computational Semantics (*SEM), and non-archival paper at the NAACL 2022 Student Research Workshop (NAACL-SRW). Seattle, Washington, July 2022.
Sabine Schulte im Walde, Diego Frassinelli
Distributional Measures of Semantic Abstraction [doi/supplement/preprint pdf/bib]
Frontiers in Artificial Intelligence: Language and Computation 4:796756, 2022. Special Issue on Perspectives for Natural Language Processing between AI, Linguistics and Cognitive Science, edited by Alessandro Lenci and Sebastian Padó.
Tarun Tater, Diego Frassinelli, Sabine Schulte im Walde
Concreteness vs. Abstractness: A Selectional Preference Perspective [pdf/bib]
In: Proceedings of the AACL-IJCNLP 2022 Student Research Workshop (AACL-IJCNLP-SRW). Taipei, Taiwan, November 2022.
Tarun Tater, Diego Frassinelli, Sabine Schulte im Walde
AbsVis — Benchmarking How Humans and Vision-Language Models "See" Abstract Concepts in Images — SAC Highlight [pdf/poster/resource]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP). Suzhou, China, November 2025.
Tarun Tater, Sabine Schulte im Walde, Diego Frassinelli
Evaluating Semantic Relations in Predicting Textual Labels for Images of Abstract and Concrete Concepts [pdf/poster]
In: Proceedings of the Cognitive Modeling and Computational Linguistics Workshop (CMCL). Bangkok, Thailand, August 2024.
Tarun Tater, Sabine Schulte im Walde, Diego Frassinelli
Unveiling the Mystery of Visual Attributes of Concrete and Abstract Concepts: Variability, Nearest Neighbors, and Challenging Categories [pdf/poster/resource]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP). Miami, Florida, November 2024.
Talks + Posters with Abstracts
Annerose Eichel, Sabine Schulte im WaldeA Dataset for Physical and Abstract Plausibility and Sources of Human Disagreement [abstract/poster]
29th Conference on Architectures and Mechanisms of Language Processing (AMLaP)
San Sebastian, Spain, August 31-September 2, 2023
Anna Hülsing, Sabine Schulte im Walde
Cross-Lingual Metaphor Detection for Low-Resource Languages [abstract]
Workshop on Computational Approaches to Metaphor and Figurative Language at the Annual Meeting of the DGfS
Universität Bochum, February 28-March 1, 2024
Urban Knupleš, Diego Frassinelli, Sabine Schulte im Walde
Investigating the Nature of Disagreements on Mid-Scale Ratings: A Case Study on the Abstractness-Concreteness Continuum [abstract/poster]
DGfS-CL Poster Session 2024 at the Annual Meeting of the DGfS
Universität Bochum, February 28-March 1, 2024
Prisca Piccirilli, Sabine Schulte im Walde
Conditions for Perceived Metaphoricity in Discourses: Two Crowdsourcing Studies [abstract]
6th International Conference on Figurative Thought and Language (FTL)
Poznan, Poland, April 20-24, 2022
Tarun Tater, Sabine Schulte im Walde, Diego Frassinelli
Evaluating Semantic Relations in Predicting Textual Labels for Images of Abstract and Concrete Concepts
2nd Workshop on Linguistic Insights from and for Multimodal Language Processing (LIMO)
Vienna, Austria, September 13, 2024
Publication: Tater et al. (CMCL 2024)
Invited Talks
Diego FrassinelliUniversity of Bologna, Department of Modern Languages, Literatures, and Cultures
From Bananas to Justice: Modeling Abstractness Across Text and Images
February 13, 2026
Diego Frassinelli
Universität Bamberg, Research Seminar @ Bamberg NLP-Group
Exploring the Multimodal Nature of Concrete and Abstract Concepts
January 28, 2026
Sabine Schulte im Walde
Utrecht University, AI & Data Science
Visual Attributes & Visualisation of Abstract and Complex Concepts
June 11, 2025
Diego Frassinelli
Gothenburg University, Centre for Linguistic Theory and Studies in Probability (CLASP)
Beyond Words: The Multimodal Nature of Concrete and Abstract Concepts
February 12, 2025
Sabine Schulte im Walde
Workshop on Computational Approaches to Metaphor and Figurative Language
Annual Meeting of the DGfS, Universität Bochum
Interactions of Figurative Language, Abstractness and Plausibility in Verb-Object Event Descriptions
February 28-March 1, 2024
Diego Frassinelli
Universität Augsburg, Computational Linguistics Research Colloquium
The Abstractness of Words and Concepts: Integrating human ratings, textual co-occurrences, and visual representations
January 31, 2024
Sabine Schulte im Walde
Universität Göttingen, LinG/RTG Colloquium of the Research Training Group 2636 Form-Meaning Mismatches
Computational Models of Figurative Language and the Role of Abstractness
July 6, 2023
Diego Frassinelli
University of Florence, Progetto Dipartimenti di Eccellenza - DILEF
Classifying Concrete vs. Abstract Words Using Textual and Visual Representations
March 17, 2023
Sabine Schulte im Walde
Universität Düsseldorf, Computational Linguistics Research Colloquium
Computational Models of Figurative Language and the Role of Abstractness
February 4, 2022
Resources and Tools
AbsVisA dataset containing 675 images annotated with 14,175 concept–explanation pairs from humans and two vision-language models
Discourse-Met-Lit and Met-Lit-Contrast
Two small-scale vs. large-scale corpora with synonymous literal and metaphorical English expressions in discourse
kNN-MultiLingConcGenerator
A tool for language-agnostic automatic extrapolation of concreteness ratings
N-ArabicConcNorms
A dataset of 202 Modern Standard Arabic nouns with human concreteness ratings
N-RomanianConcNorms
A dataset of 300 Romanian nouns with human concreteness ratings
NN-ComposiGen
Two datasets of 200+88 English noun compounds with compositionality and abstractness ratings, plus images
VO-ImageGen
40 English verb-object event pairs balanced for concreteness ratings, plus generated images and figurative language judgements (incl. example sentences)
VO-MultiLingConcMet
A dataset containing 5,814/430,000 collected/LLM-extrapolated multilingual concreteness ratings for verb-object events in English, German, and Slovene, plus figurative language judgements (incl. example sentences)
VO-LIMONATE
Cross-lingual transfer of literal and metaphorical language and conventionality
VO-SVO-EnglishConcMet
A dataset containing approx. 4,000/500 English verb-object/subject-verb-object events with concreteness ratings and figurative language judgements (incl. example sentences)
SVO-PAP-Met
A dataset containing physical and abstract plausibility ratings for English subject-verb-object events, figurative language judgements (incl. example sentences), and sources of human disagreement
Events
Introductory Course at the 33rd European Summer School in Logic, Language and Information (ESSLLI)Cognitive and Computational Models of Abstractness
Diego Frassinelli, Sabine Schulte im Walde
National University of Ireland Galway, August 8-12, 2022
MUDCAT Opening Workshop
Guests: Alessandro Lenci (Universita di Pisa), Gabriella Vigliocco (University College London)
May 20-21, 2022
MUDCAT Closing Workshop
March 9-14, 2026